Kapoor et al (2024): Qualitative Insights Tool (QualIT): LLM Enhanced Topic Modeling
💡 1. Research Question and Research Gap
To what extent can LLM-based topic modeling outperform LDA and BERTopic in extracting coherent and diverse topics from large text datasets?
To answer this question, the research team proposes Qualitative Insights Tool (QualIT), a novel LLM-based thematic modeling framework, and conducts comparative experiments with LDA and BERTopic based on the 20 NewsGroups dataset.
🌊 2. Introduction
Topic modeling is a representative NLP technique for automatically extracting latent topics from documents. Traditional methods like LDA generate topics based on word co-occurrence patterns, but they have limitations in capturing subtle contextual or semantic nuances within sentences. Recently, approaches leveraging large language models (LLMs) such as BERT and GPT have enabled more sophisticated semantic understanding, and embedding-based techniques like BERTopic have gained attention. However, BERTopic also has limitations, as it typically assigns only a single topic to each document, making it insufficient for capturing multiple topics within a single document. To address this issue, this paper proposes LLM-enhanced Topic Modeling, which combines the semantic understanding capabilities of LLMs with clustering techniques.
🛠️ 3. Data and Methodology
📂 Dataset
- 20 NewsGroups: A public dataset containing 20,000 news articles
- Preprocessing: Lowercasing, stopword removal, and lemmatization
🧠 Models for Comparison
- LDA (Latent Dirichlet Allocation): Implemented using Gensim with default parameters
- BERTopic: Utilizes embedding vectors and HDBSCAN-based clustering
- QualIT (LLM-based approach): Based on Claude-2.1 with parameters
top_k=50,top_p=0
🔍 4. LLM-Enhanced Topic Modeling Method
🔹 Step 1: Extract Keyphrases
Each document is processed by an LLM to extract multiple meaningful keyphrases. Unlike traditional models (e.g., LDA, BERTopic) that assume a single topic per document, this step captures multiple thematic cues within one text. The extracted phrases serve as essential features for topic classification.
🔹 Step 2: Hallucination Verification
A coherence score based on cosine similarity is calculated to assess how well each keyphrase aligns with the document content. Keyphrases with low scores are identified as “AI hallucinations” and removed, leaving only contextually valid and reliable terms for further analysis.
🔹 Step 3: Clustering (Main & Sub-Topics)
Refined keyphrases are grouped using a K-Means clustering algorithm.
Clustering is conducted in two stages:
- Main Topics: Documents with similar keyphrase patterns are grouped to identify overarching themes.
- Sub-Topics: Within each main topic, a second clustering step is applied to extract more detailed and specific themes.
For each sub-cluster, the LLM is prompted again to analyze compressed content and generate representative sub-topics.
✅ 5. Experimental Setup & Results
🔹 Dataset and Model Configuration
- The experiments were conducted using the 20 NewsGroups dataset, which contains approximately 20,000 news articles categorized into 20 topics.
- LDA and BERTopic were run with default parameters, while the LLM-based method (QualIT) used the Claude-2.1 model.
- Key parameters:
top_k = 50,top_p = 0(optimized for document-level semantic coherence)
- Key parameters:
🔹 Evaluation Metrics
- Topic Coherence: Measures how semantically similar the top-ranked words in each topic are.
- Topic Diversity: The percentage of unique words across all topic outputs (from 0 to 1).
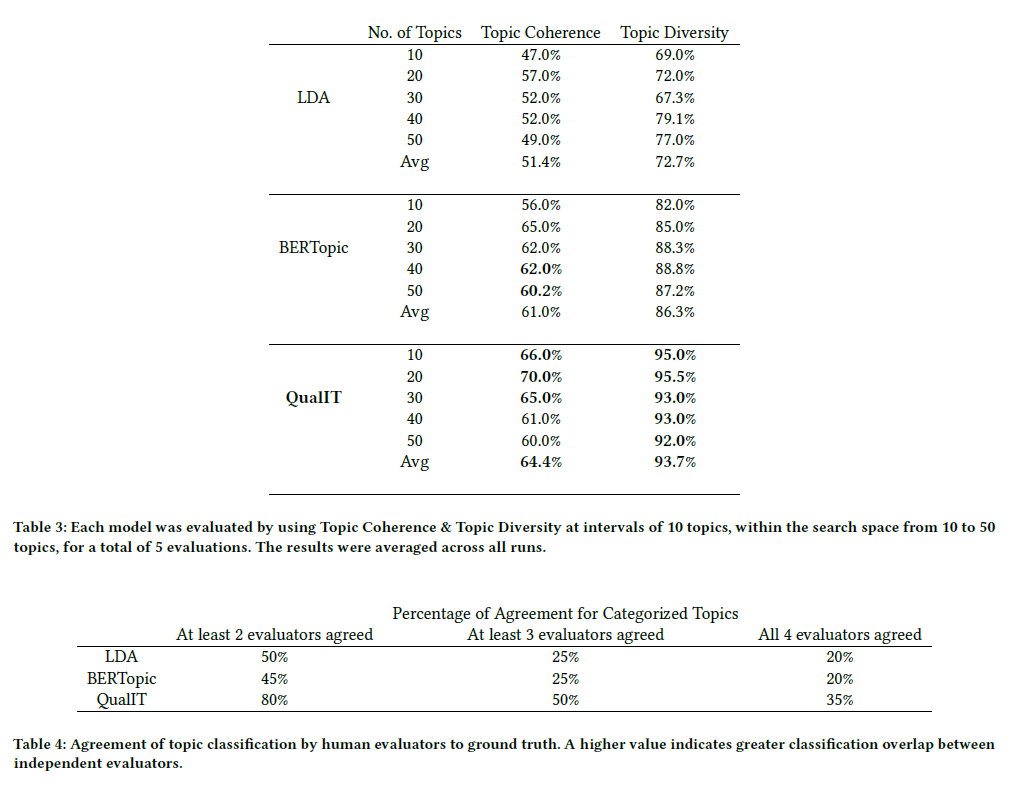
🔹 Table 3: Topic Coherence & Diversity by Number of Topics
This table compares the performance of three topic modeling methods — LDA, BERTopic, and QualIT — in terms of Topic Coherence and Topic Diversity, evaluated across different numbers of topics (10 to 50).
✅ LDA
- Best coherence: 57.0% at 20 topics
- Best diversity: 79.1% at 40 topics
- Average performance: 51.4% coherence, 72.7% diversity
- As a traditional approach, LDA shows the lowest scores overall in both coherence and diversity.
✅ BERTopic
- Best coherence: 65.0% at 20 topics
- Best diversity: 88.8% at 40 topics
- Average performance: 61.0% coherence, 86.3% diversity
- With embedding-based clustering, BERTopic outperforms LDA and offers moderate diversity and coherence.
✅ QualIT
- Best coherence: 70.0% at 20 topics
- Best diversity: 95.5% at 20 topics
- Average performance: 64.4% coherence, 93.7% diversity
- QualIT consistently performs the best across all topic counts. It is especially optimized for 20 topics, which matches the dataset’s ground-truth structure.
👥 Table 4: Human Evaluation Agreement
This table shows how often human evaluators (4 total) agreed on categorizing topic outputs from each model into one of the 20 ground-truth classes.
✅ QualIT
- 80% agreement with at least 2 evaluators
- 50% agreement with at least 3 evaluators
- 35% full agreement (all 4 evaluators)
- QualIT provides topic outputs that are much clearer and easier for humans to interpret and classify consistently.
✅ BERTopic & LDA
- LDA: 50% (2 evaluators), 25% (3 evaluators), 20% (all 4)
- BERTopic: 45%, 25%, 20% respectively
- Both LDA and BERTopic yield lower agreement scores, indicating more ambiguous or inconsistent topic groupings.
⚠️ 6. Limitations & Future Work
- Processing Time
- QualIT takes approximately 2–3 hours per run
- BERTopic completes in about 30 minutes
→ Reducing runtime is essential for large-scale deployments.
- Clustering Algorithm Improvements
- Currently uses K-Means, which requires predefined cluster numbers
- HDBSCAN, used in BERTopic, may provide more adaptive and nuanced topic boundaries
- Future work may explore replacing K-Means with HDBSCAN to improve granularity and accuracy
🧾 7. Conclusion
- QualIT integrates the semantic understanding of LLMs with the structural power of clustering algorithms, delivering more coherent and diverse topics than traditional methods like LDA and BERTopic.
- Especially useful in qualitative text analysis scenarios where interpretability and depth matter.
- Future directions may include:
- Multilingual support
- Efficiency improvements
- Advanced clustering
A Comparative Study in Topic Modeling
📦 1. Dataset and Preprocessing
🔹 Source
Video_Games.jsonl from Amazon Reviews dataset
🔹 Preprocessing
Filtered only 1-star reviews with helpful_votes >= 1
Text length between 20 and 200 characters
Removed stopwords, applied lemmatization
Final dataset prepared for topic modeling
- Preprocess Text Data
def preprocess_text(text):
text = re.sub('\s+', ' ', text) # Remove extra spaces
text = re.sub('\S*@\S*\s?', '', text) # Remove emails
text = re.sub('\'', '', text) # Remove apostrophes
text = re.sub('[^a-zA-Z]', ' ', text) # Remove non-alphabet characters
text = text.lower() # Convert to lowercase
return text
- Tokenize and Remove Stopwords
# Download NLTK stopwords
nltk.download('stopwords')
stop_words = stopwords.words('english')
# Tokenize and remove stopwords
def tokenize(text):
tokens = gensim.utils.simple_preprocess(text, deacc=True)
tokens = [token for token in tokens if token not in stop_words]
return tokens
- Lemmatize Tokens ```python try: nltk.data.find(‘corpora/wordnet’) except LookupError: nltk.download(‘wordnet’)
lemmatizer = WordNetLemmatizer()
def extract_lemmas(tokens): return [lemmatizer.lemmatize(token) for token in tokens]
4. Create Dictionary and Corpus
```python
# Create dictionary and corpus
id2word = corpora.Dictionary(df['lemmas'])
texts = df['lemmas']
corpus = [id2word.doc2bow(text) for text in texts]
🧠 2. Topic Modeling with LDA, BERTopic, and QualIT
LDA
lda_model = gensim.models.ldamodel.LdaModel(corpus=corpus,
id2word=id2word,
num_topics=20,
random_state=100,
update_every=1,
chunksize=100,
passes=10,
alpha='auto',
per_word_topics=True)
coherence
LDA Coherence Score: 0.30031160118766986
Diversity
Total words across all topics: 400
Unique words across all topics: 385
LDA Diversity Score (N=20): 0.9625
🔍 Interpretation
Topic coherence is moderate, which indicates that the most frequent words in each topic are somewhat semantically related.The high diversity score (96.25%) shows that across the top 20 topics, most keywords are unique, with little redundancy.However, many keywords are still general-purpose words like game, buy, use, play, which lack contextual nuance.
BERTopic
nlp = spacy.load("en_core_web_sm")
def spacy_tokenizer(text):
return [token.lemma_ for token in nlp(text) if not token.is_stop and not token.is_punct and not token.is_space]
english_stopwords = stopwords.words('english')
vectorizer_model = CountVectorizer(tokenizer = spacy_tokenizer,
stop_words=english_stopwords,
min_df=5,
max_df=0.9,
ngram_range=(1, 1))
model = BERTopic(verbose=True,
embedding_model='all-MiniLM-L6-v2', # all-MiniLM-L12-v2, paraphrase-MiniLM-L12-v2
vectorizer_model=vectorizer_model,
language='english',
nr_topics = 20,
top_n_words = 20,
calculate_probabilities=True
)
topics, probs = model.fit_transform(df.text)
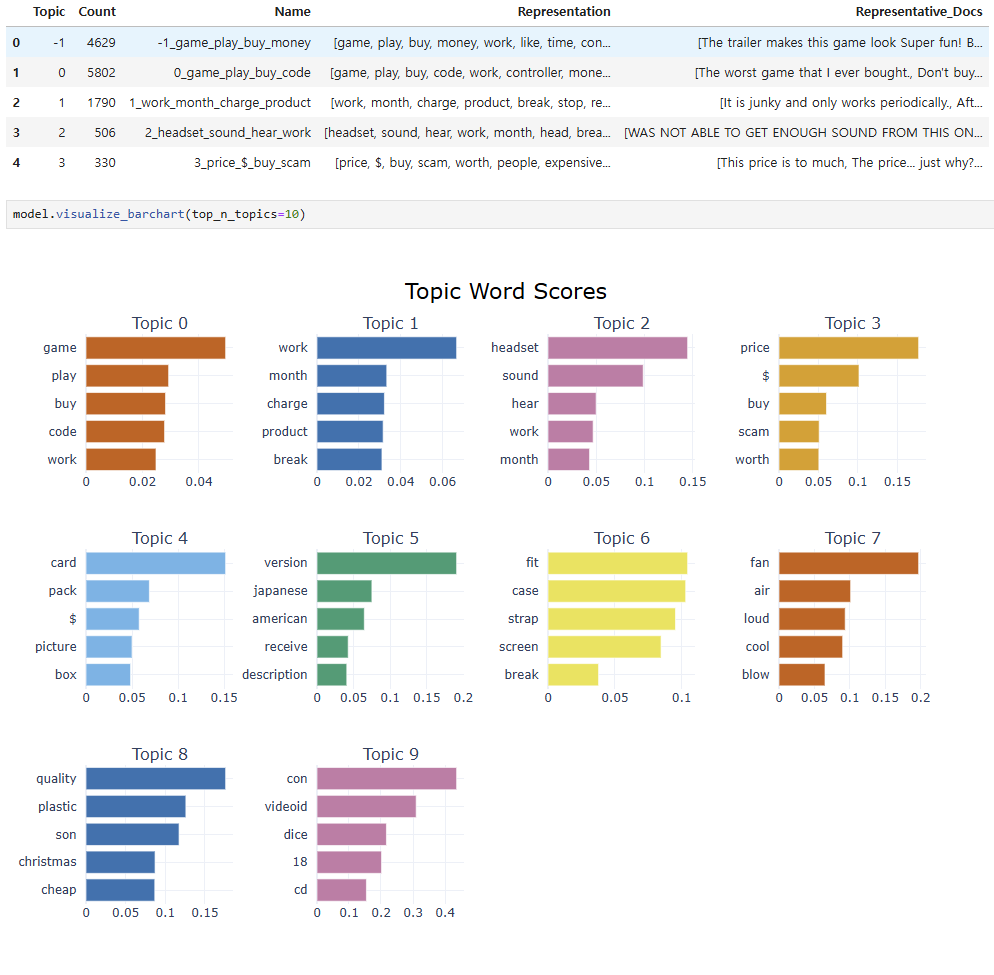
BERTopic was configured to extract 20 topics using BERT embeddings and CountVectorizer. It produced clusters with clear keyword groupings, and representative documents were extracted per topic. Topics such as: “game”, “play”, “buy”, “money” – indicate general purchasing experiences. “price”, “$”, “scam”, “worth” – highlight value dissatisfaction. “headset”, “sound”, “hear” – show technical product malfunctions.
BERTopic Coherence Score (N=20): 0.3478
BERTopic Diversity Score (N=20): 0.7211
🔍 Interpretation
BERTopic’s coherence score was 0.3478, which is higher than the LDA, indicating that the key words in each topic are more semantically related. The Diversity Score was 0.7211, which means that about 72% of the top words in the entire topic were unique words. This figure is somewhat lower than the LDA, but it can contribute to increasing semantic association and consistency by overlapping some words between topics. Overall, BERTopic is interpreted as effectively balancing the interpretability of topics with the distinction between topics.
LLM
1. Extract keywords
# GPT
def gpt_prompt(prompt):
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"model": "gpt-3.5-turbo",
"messages": [
{"role": "system", "content": "You extract keywords for analyzing customer reviews"},
{"role": "user", "content": prompt}
],
"temperature": 0.3 #control creativity
}
response = requests.post("https://api.openai.com/v1/chat/completions", headers=headers, json=data)
response.raise_for_status()
result = response.json()["choices"][0]["message"]["content"].strip()
result = " ".join(result.splitlines()).strip()
if any(bad in result.lower() for bad in ["text"]):
return "LLM Error"
return result
# Prompt
def extract_keyphrases(text, index=None, total=None):
if index is not None and total is not None:
print(f"{index + 1} / {total}")
prompt = f"""Analyze the following customer review and extract 5 to 10 key phrases that best represent the core topics, features, sentiments, and experiences mentioned in the review.
Key phrases should capture the main subjects, specific product or service attributes, common issues, or positive aspects.
Guidelines:
- Each extracted phrase must clearly represent a specific point or idea from the review.
- Formulate them as meaningful noun phrases, not just single words or a list of adjectives or verbs.
- For example: "poor battery life", "excellent customer support", "difficult assembly process".
- Output should be a single line, with key phrases separated by commas.
- DO NOT include explanatory sentences, standalone adjectives, adverbs, verbs, or full sentences.
- DO NOT infer or hallucinate meanings not present in the review.
- Only include key phrases that are explicitly stated or strongly implied in the review text.
- The extracted key phrases will be used for subsequent document clustering and topic summarization.
[Customer Review]
{text}
Key Phrases:"""
#return gemini_prompt(prompt)
return gpt_prompt(prompt)
2. Halluciation check
results = []
model = SentenceTransformer("sentence-transformers/paraphrase-MiniLM-L6-v2")
for idx, row in sub_df.iterrows():
text = str(row['text']) # original text or pre-processed text
keyphrases = str(row['Keywords']).split(',')
# embedding
text_embedding = model.encode(text, normalize_embeddings=True)
kp_embeddings = model.encode(keyphrases, normalize_embeddings=True)
# similarity score
sims = [np.dot(text_embedding, kp) for kp in kp_embeddings]
sims_score = np.mean(sims)
# filtering
valid_kps = [kp for kp, score in zip(keyphrases, sims) if score >= 0.10] # control threshold
results.append({
'original_keyphrases': keyphrases,
'coherence_score': sims_score,
'valid_keyphrases': valid_kps,
})
3. clustering
def embed_text(text):
try:
return model.encode(str(text), normalize_embeddings=True)
except:
return np.zeros(model.get_sentence_embedding_dimension())
# embed text
sub_df['embedding'] = sub_df['valid_keyphrases'].apply(embed_text)
embeddings = np.vstack(sub_df['embedding'].values)
# K-Means clustering
n_clusters = 5 # of clusters
kmeans = KMeans(n_clusters=n_clusters, random_state=42)
sub_df['cluster'] = kmeans.fit_predict(embeddings)
sub_df['cluster'].value_counts().sort_index()
# 5. aggregate keywords by cluster
cluster_docs = (
sub_df[sub_df["cluster"] != -1]
.explode("valid_keyphrases")
.groupby("cluster")["valid_keyphrases"]
.apply(lambda s: " ".join(s.astype(str)))
.to_dict()
)
# 6. top keywords by cluster
vectorizer = TfidfVectorizer(max_features=1000)
top_terms_per_cluster = {}
for cluster_id, text in cluster_docs.items():
tfidf = vectorizer.fit_transform([text])
feature_array = np.array(vectorizer.get_feature_names_out())
tfidf_sorting = np.argsort(tfidf.toarray()).flatten()[::-1]
top_terms = feature_array[tfidf_sorting][:20]
top_terms_per_cluster[cluster_id] = top_terms.tolist()
# 7. result
print("\n Top keywords by cluster:\n")
for cid, terms in top_terms_per_cluster.items():
print(f"Cluster {cid}: {' / '.join(terms)}")
Top keywords by cluster:
-
Cluster 0
in,charged,plugged,pre,money,edition,fire,not,all,stars,
switch,issue,work,hazard,didn,does,dlc,hot,digital,fully -
Cluster 1
xbox,waste,problems,one,cent,better,of,working,way,live,
hell,for,fps,frustration,get,go,ignored,mac,in,false -
Cluster 2
not,headset,worth,it,issue,of,card,to,cord,disappointment,
this,resolution,genitalia,connect,stick,cards,on,overspending,customization,cut -
Cluster 3
game,of,time,the,games,waste,money,issue,play,not,
in,experience,compatibility,playing,player,copy,online,connection,for,buy -
Cluster 4
issue,not,working,disappointed,malfunction,compatibility,product,with,amazon,game,
arrival,missing,be,failure,doesn,open,returning,disconnects,disk,do
LLM Coherence Score (avg): 0.4068
LLM Diversity Score (N=20): 0.8400
🔍 Interpretation
The LLM-based model had the highest coherence score of 0.4068, which was the highest among the three models. This means that the keywords in each topic are most meaningfully linked to the document. The diversity score of 0.84 is also high, showing that the keywords across the entire topic are properly distributed. Although it is somewhat lower than the LDA, LLM is designed to meaningfully utilize overlapping keywords by extracting context-based keyphrases and removing “Hallucination.”
📊 3. Coherence & Diversity Score Comparison
| Model | Coherence Score | Diversity Score |
|---|---|---|
| LDA | 0.3003 | 0.9625 |
| BERTopic | 0.3478 | 0.7211 |
| LLM (QualIT) | 0.4068 | 0.8400 |
🔍 Interpretation
The table shows that LLM (QualIT) outperforms the other models in topic coherence, meaning it generates more semantically consistent topics. While LDA achieves the highest diversity score, indicating broader coverage of unique words, it lacks semantic depth. BERTopic offers a good balance but falls between the two in both metrics. Overall, LLM is the most effective model in terms of producing both meaningful and distinguishable topics.