🎬 Movie Review Text Mining: Sentiment Analysis of Avengers: Endgame
🎥 1. Introduction
Avengers: Endgame was one of the most globally successful films of the last decade.
Both Korean and American audiences rated the movie extremely highly.
- 🇺🇸 Rotten Tomatoes (U.S.): 8.4 / 10
- 🇰🇷 Naver Movie (Korea): 9.5 / 10
At first glance, the conclusion seems simple -> Both countries loved the movie.
But here’s the real question 👇
If both countries gave similarly high ratings, does a high rating always mean strong positive emotion in text?
This project investigates that question using Natural Language Processing (NLP)
🎯 2. Research Objective
The goal of this project is to analyze and compare movie reviews of Avengers: Endgame from the United States and Korea using text mining techniques.
More specifically, this study aims to:
- 🔍 Compare frequently used words in U.S. and Korean reviews
- 📊 Analyze sentiment distributions in both countries
- 🤔 Examine why high ratings may still produce different sentiment patterns
- 🌏 Explore whether cultural communication styles influence sentiment detection
Although both countries rated the movie highly, the distribution of textual sentiment may reveal deeper structural differences.
This is not just about whether people liked the movie. It is about how emotion is linguistically encoded across cultures.
📚 3. Theoretical Background
3.1 ⭐ Star Ratings vs Textual Sentiment
Prior research suggests that star ratings and textual sentiment do not always align.
Wan & Nakayama (2022) demonstrated that numerical ratings reflect overall satisfaction, while textual reviews often capture more nuanced emotional expression.
This means:
- Two countries may assign similar ratings
- But differ in emotional intensity within the text
So relying solely on rating scores may hide cross-cultural variation in how emotions are expressed.
3.2 🌏 Cultural Communication Styles
Cultural communication theory provides an additional lens.
According to cross-cultural communication research (e.g., Brand et al., 2022), cultures can be broadly categorized.
In high-context cultures:
- Communication tends to be indirect and subtle
- Emotional evaluation is often implied rather than explicitly stated
In low-context cultures:
- Communication is explicit and direct
- Emotional reactions are often expressed with strong evaluative words
This distinction is important because sentiment analysis models rely heavily on explicit emotional vocabulary.
If emotion is expressed indirectly, a model may struggle to detect it accurately.
📦 4. Data Collection 📦
To explore this question, I collected movie review data from two major platforms:
- 🇺🇸 Rotten Tomatoes
- 🇰🇷 Naver Movie
Dataset Overview
- 📄 Total reviews: 600
- 🇺🇸 300 English reviews
- 🇰🇷 300 Korean reviews
- 📝 Text-only reviews (free-text format)
- Each dataset contains a single column:
review
All reviews were manually collected from publicly available sources and stored in CSV format.
🟥 USA
🔹Data Processing
1. Preprocess Text Data
def clean_text(text):
text = str(text) # make sure it is a string
text = re.sub(r'\n', ' ', text) # remove new lines
text = re.sub(r'\r', '', text) # remove return marks
text = re.sub(r'\t', ' ', text) # remove tabs
text = re.sub(r'\.', '', text) # remove dots
text = re.sub(r"[^A-Za-z\s]", "", text) # remove special marks, keep letters
text = re.sub(r'\d+', '', text) # remove numbers
text = re.sub(r'\s+', ' ', text) # fix many spaces to one
text = text.strip().lower() # cut side spaces and lowercase
2. Remove Stopword and Domain-Specific Word
stop_words = set(stopwords.words("english"))
keep_words = {"not", "no", "nor", "but", "however", "though", "although", "without"}
stop_words = stop_words - keep_words
domain_stopwords = {
"movie", "film", "movies", "films",
"cinema", "endgame", "marvel",
"avengers", "mcu", "infinity"
}
def remove_stopwords(text):
tokens = [
w for w in text.split()
if w not in stop_words
and w not in domain_stopwords
and len(w) > 2
]
return tokens
3. Normalization & Lemmatization
lemmatizer = WordNetLemmatizer()
def normalize_and_lemmatize(tokens):
# normalize films → movie
tokens = [re.sub(r"\bfilms?\b", "movie", w) for w in tokens]
# apply lemmatization
tokens = [lemmatizer.lemmatize(w) for w in tokens]
return tokens
🔹Word Frequency Analysis (U.S. Reviews)
The bar chart below presents the top 30 most frequent words in U.S. reviews.
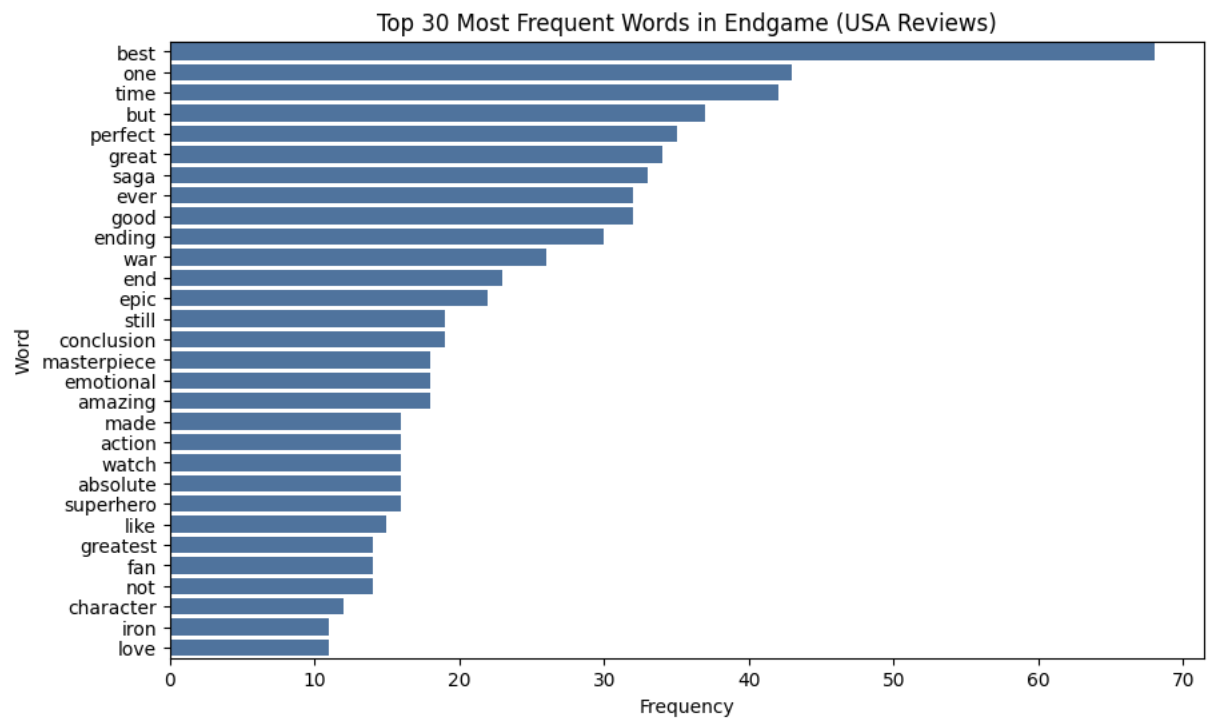
Strong evaluative terms such as best, perfect, great, and amazing dominate the ranking. This indicates that American reviewers frequently rely on direct and high-intensity emotional vocabulary.
🔹Word Cloud Visualization
To complement the frequency distribution, a word cloud was generated to visualize important words.
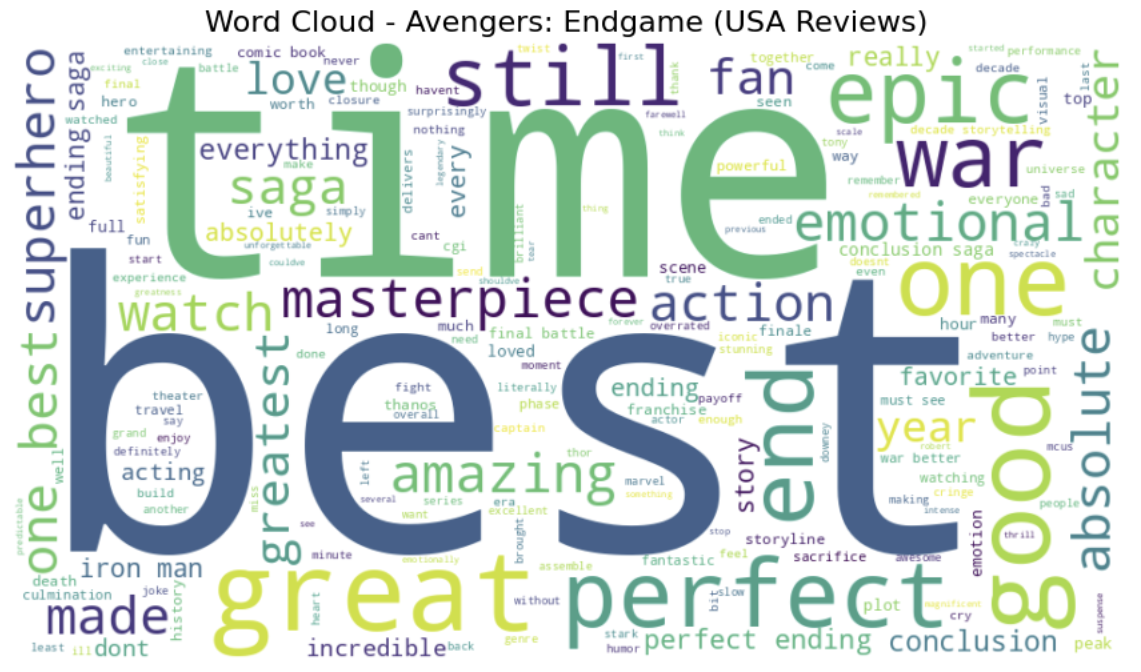
The visual dominance of words like best, time, great, and perfect reinforces the observation that positivity is expressed explicitly and emphatically. While the bar chart provides precise rankings, the word cloud highlights the emotional intensity embedded in word choice.
🔹 Sentiment Analysis (VADER)
To quantify emotional polarity in U.S. reviews, I applied VADER (Valence Aware Dictionary and sEntiment Reasoner) — a lexicon-based sentiment analysis model designed for social and review text.
VADER computes a compound sentiment score ranging from -1 (most negative) to +1 (most positive).
Compute Sentiment Scores
# Sentiment Analysis (VADER)
sia = SentimentIntensityAnalyzer()
# Calculate sentiment scores (VADER compound score for each cleaned review)
df["sentiment_score"] = df["clean_review"].apply(lambda x: sia.polarity_scores(x)["compound"])
def classify(score):
if score > 0:
return "positive"
elif score < 0:
return "negative"
else:
return "neutral"
# Apply classification to each sentiment score
df["sentiment"] = df["sentiment_score"].apply(classify)
Reviews were categorized based on compound score:
Positive → score > 0
Negative → score < 0
Neutral → score = 0
🔹 Sentiment Distribution (U.S. Reviews)
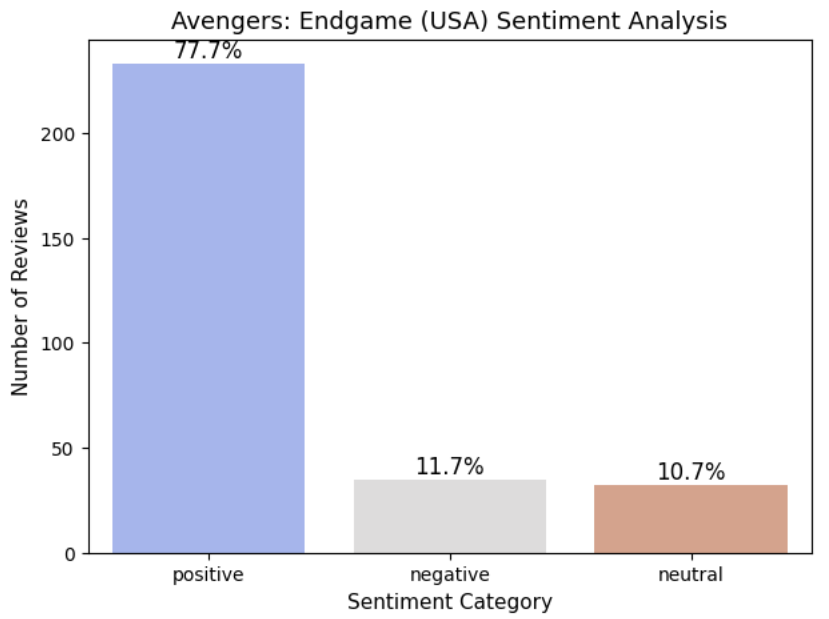
The overwhelming dominance of positive reviews indicates that American audiences expressed strong approval of the film. This result aligns closely with the earlier word frequency analysis, where highly evaluative terms such as best, perfect, great, and amazing appeared frequently. This shows that American reviewers tend to express their emotions strongly and directly.
🟦 KOREA
🔹 Data Processing
1. Preprocess Text Data
def clean_korean_text(text):
text = str(text)
text = re.sub(r'\n', ' ', text) # Remove line breaks
text = re.sub(r'\r', '', text) # Remove carriage returns
text = re.sub(r'\t', ' ', text) # Remove tab characters
text = re.sub(r'[~!@#$%^&*()_+=<>?/.,:;\'\"”“‘’…★☆♥♡]', '', text) # Remove special symbols
text = re.sub(r'\d+', '', text) # Remove numbers
text = re.sub(r'[ㄱ-ㅎㅏ-ㅣ]+', '', text) # Remove isolated Korean consonants/vowels (e.g., ㅋㅋ, ㅎㅎ)
text = re.sub(r'\s+', ' ', text) # Remove multiple spaces
text = text.strip()
2. Remove Stopword and Domain-Specific Word
stop_words = [
# Particles, endings, and adverbs (grammatical function words)
"은", "는", "이", "가", "을", "를", "의", "에", "에서", "으로", "로", "와", "과",
"도", "만", "보다", "처럼", "까지", "께서", "한테", "에게", "라고",
"그리고", "그래서", "하지만", "그러나", "또", "또한", "근데", "그런데",
"뭔가", "좀", "너무", "정말", "진짜", "완전", "아주", "많이", "되게", "그냥",
"이건", "저건", "그건", "우리", "내가", "이번", "이제", "또는", "다시",
"하다", "이다",
# Interjections and onomatopoeia (do not contribute directly to sentiment)
"와", "아", "어", "음", "헐", "ㅋㅋ", "ㅎㅎ", "ㅠ", "ㅜ", "ㄷㄷ", "하하", "휴", "캬",
# Miscellaneous unnecessary words
"때문", "정도", "것", "거", "게", "수", "듯", "요", "죠", "네", "데", "중", "영화", "마블", "엔드게임",
"건가", "인가", "거나", "라도", "거든요", "네요", "입니다", "했습니다", "봤어요","어벤져스", "재미있다"
]
3. Normalization & Tokenization
okt = Okt()
def normalize_and_tokenize(text):
# tokenization
tokens = okt.morphs(text, stem=True) # It is a morphological analysis function that splits a sentence into individual word units.
# stopword removal and length filtering
tokens = [w for w in tokens if w not in stop_words and len(w) > 1]
return " ".join(tokens)
🔹 Word Frequency Analysis (Korean Reviews)
The bar chart below presents the top 30 most frequent words in Korean reviews.
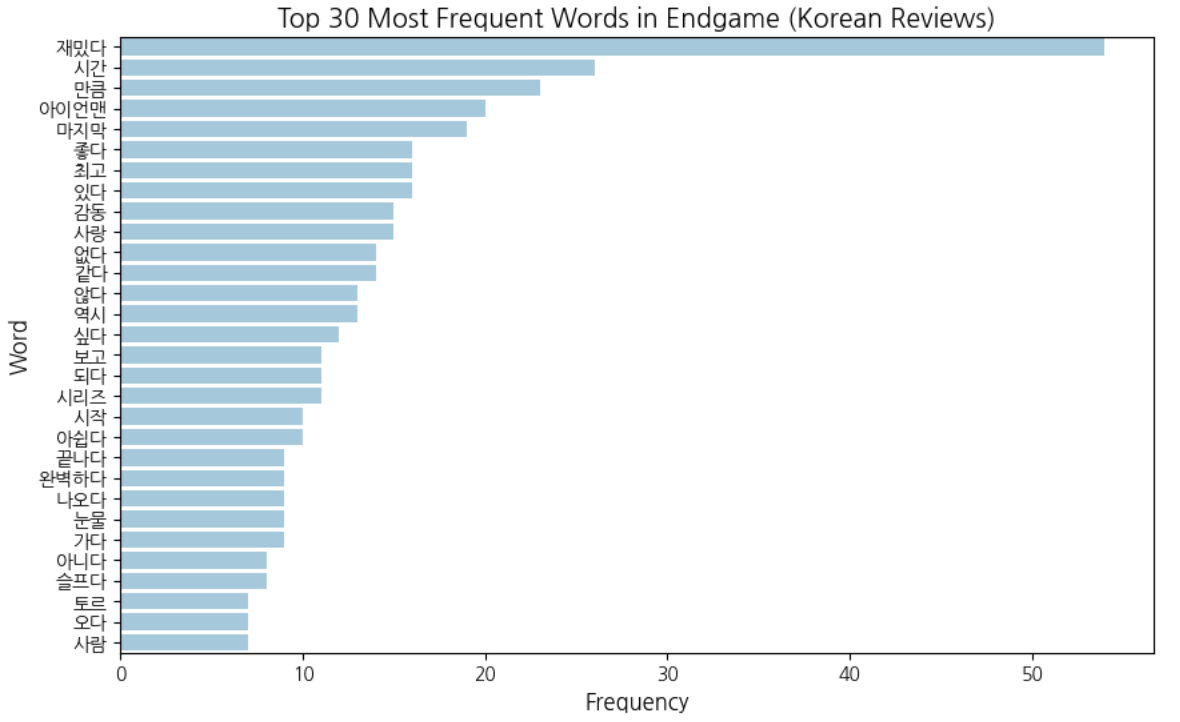
Words such as 재밌다 (fun), 좋다 (good), 최고 (the best), and 감동 (emotion) appear frequently, indicating clear positive sentiment. At the same time, experiential words like 시간 (time), 마지막 (last), and 시리즈 (series) are also prominent. This suggests that Korean reviewers express emotion clearly, but often within a broader narrative or situational context rather than relying solely on intensifiers.
🔹 Word Cloud Visualization
To complement the frequency distribution, a word cloud was generated to visualize important words in Korean reviews.

The word cloud highlights emotional terms such as 재밌다, 좋다, and 감동, but it also emphasizes relational and experiential words like 보다 (to watch), 시리즈 (series), and 시간 (time). Compared to the U.S. reviews, Korean reviews still contain strong emotional expressions, but these words coexist with contextual and narrative terms. This pattern suggests that emotional expression in Korean reviews is often intertwined with storytelling and experiential reflection rather than expressed purely through intensifiers.
🔹 Sentiment Analysis (KNU Sentiment Lexicon)
To quantify emotional polarity in Korean reviews, I applied a lexicon-based sentiment analysis approach using the KNU Korean Sentiment Lexicon.
The KNU lexicon was constructed from a large Korean lexical database using deep learning-based classification of dictionary definitions.
Unlike VADER, this method does not generate a normalized compound score. Instead, it computes the overall sentiment score by summing the polarity values of all matched sentiment words within each review.
Compute Sentiment Scores
# Load the sentiment lexicon
knu_lex = pd.read_csv("knu_sentiment_lexicon.csv")
# Convert lexicon into dictionary
sentiment_dict = dict(zip(knu_lex["word"], knu_lex["polarity"]))
# Function to calculate sentiment score
def get_sentiment_score(text):
tokens = okt.morphs(text)
score = 0
for word in tokens:
if word in sentiment_dict:
score += sentiment_dict[word]
return score
# Apply sentiment scoring
df_kor["sentiment_score"] = df_kor["clean_review"].apply(get_sentiment_score)
def classify(score):
if score > 0:
return "positive"
elif score < 0:
return "negative"
else:
return "neutral"
df_kor["sentiment"] = df_kor["sentiment_score"].apply(classify)
Reviews were categorized based on compound score:
Positive → score > 0
Negative → score < 0
Neutral → score = 0
🔹 Sentiment Distribution (Korean Reviews)
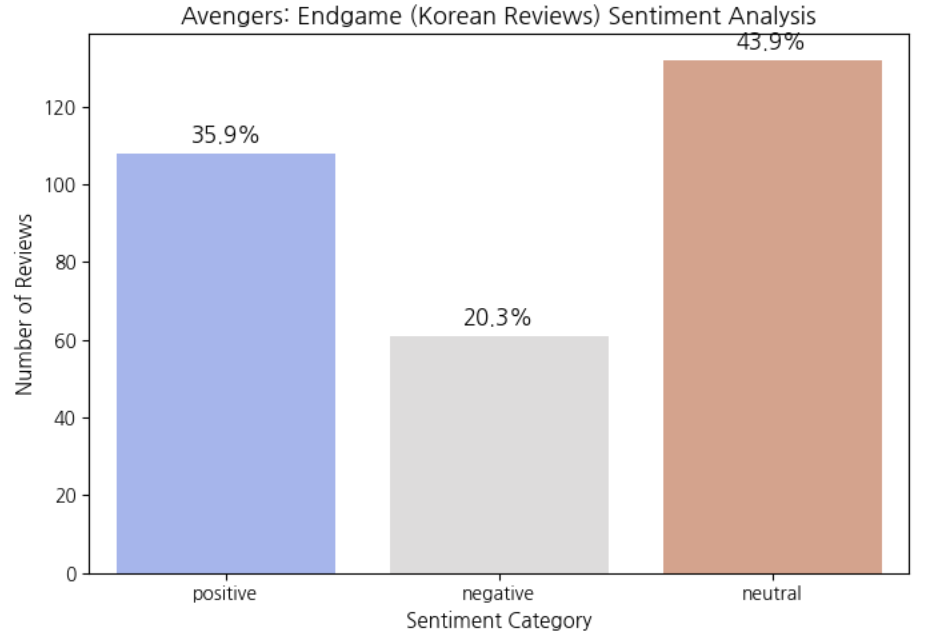
The sentiment distribution reveals a noticeably different pattern from the U.S. results. Unlike the U.S. reviews, where positive sentiment overwhelmingly dominated, Korean reviews show a much larger proportion of neutral classifications. Although positive reviews still form a substantial portion, the high neutral ratio suggests that Korean audiences often express their opinions in a more subtle and context-dependent manner rather than through strongly polarized wording.
🔎 Interpretation & Conclusion
1️⃣ Key Interpretation
Although both U.S. and Korean audiences gave Avengers: Endgame very high overall ratings, the sentiment distributions revealed a noticeable difference.In the U.S. dataset, approximately 77.7% of reviews were classified as positive. This indicates that American reviewers tended to express their approval clearly and strongly. The frequent use of highly evaluative words such as best, perfect, and amazing further supports this pattern.In contrast, Korean reviews showed only 35.9% positive, while 43.9% were classified as neutral. Despite the high overall rating in Korea (9.5/10) and the presence of many positive words in the frequency analysis, the sentiment model detected a much larger proportion of neutral expressions.This suggests that the difference is not necessarily about how much audiences liked the movie, but rather how they expressed their emotions linguistically.
2️⃣ Cultural Communication Style
One possible explanation for this pattern lies in cultural communication differences.
The United States is generally considered a low-context culture, where communication is explicit, direct, and emotionally transparent. Reviewers tend to use strong evaluative expressions such as:
- “It was amazing.”
- “This movie was absolutely terrible.”
These statements contain clear emotional signals, making it easier for sentiment analysis models to detect strong positive or negative polarity.
Korea, on the other hand, is often described as a high-context culture, where communication tends to be more subtle, indirect, and context-dependent. Instead of directly stating strong evaluations, reviewers may express their opinions through experiential descriptions, such as:
- “I lost track of time while watching it.”
- “I fell asleep while watching it.”
Although these sentences imply strong positive or negative reactions, they do not always contain explicit emotional keywords. As a result, lexicon-based sentiment models may classify them as neutral or low-intensity sentiment.
3️⃣ Final Conclusion
Overall, both U.S. and Korean audiences reacted positively to Avengers: Endgame. However, the sentiment analysis results reveal that emotional intensity and linguistic expression differ across cultures. The U.S. reviews demonstrated high-intensity, explicit sentiment expression, resulting in a dominant positive classification. In contrast, Korean reviews exhibited more balanced and context-driven emotional expression, leading to a higher proportion of neutral classifications. Therefore, sentiment analysis does not only measure audience preference. It also reflects deeper cultural patterns in how emotions are communicated through language. This study highlights the importance of considering cultural communication style when interpreting cross-linguistic sentiment analysis results.